
An Introduction to Reinforcement Learning: What is it, and what can it be used for?

Thomas Andersen
May 5, 2024
Are you curious about how machines can learn by experience and improve over time? At Digel, we believe that Reinforcement Learning (RL) can be the key framework for optimizing industrial processes. In this blog post, I will give you a simple introduction to RL, how it works, what separates it from other machine learning methods, and some use cases.
The Three Classes of Machine Learning
Within the world of machine learning (ML), we typically categorize methods of learning into three classes: supervised learning, unsupervised learning, and RL.
In supervised learning, a dataset that maps inputs to correct outputs is used for training the AI agent. Supervised learning is often used for image classification, e.g., classifying animals in pictures. The dataset used to train the animal-classifying agent will typically consist of images of a broad range of species, each individually labeled with the species name. This is why we call it supervised learning since the learning process is guided by a 'supervisor' that provides correct answers for each example in the training data. The AI agent learns to associate input images with the correct labels through this process, improving its accuracy over time.
On the other hand, unsupervised learning is a set of methods that try to identify patterns and relationships within the data. A typical unsupervised learning approach is clustering techniques, i.e., grouping similar data points together. If we continue with our dataset of animal species, we may reformulate the classification problem to an unsupervised learning problem where we find similarities between species from the images without prior knowledge of the animal names.
With RL, the AI agent learns by interacting with its environment. The agent receives feedback from the environment in the form of rewards or penalties based on its actions. Through trial and error, the agent aims to maximize its rewards over time (and minimize penalties) to find an optimal action to take at any given state. Continuing with our animal-themed examples, we might want to try to train an RL agent to survive in nature. The agent will receive a reward for every encounter with an animal where the agent stays alive and will receive a penalty for encounters with predators that eat the agent. By simulating enough encounters with different species, the agent will learn to avoid a set of species.
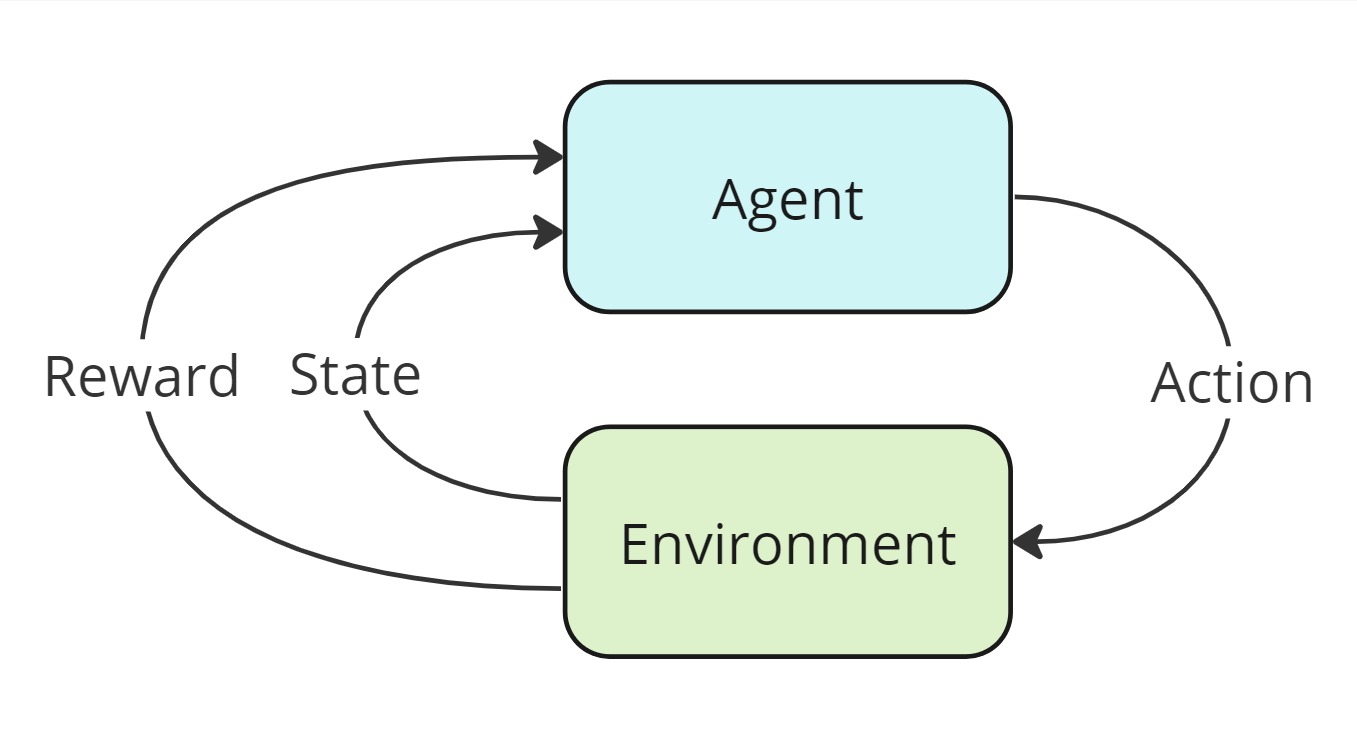
The basic components of all reinforcement learning architectures consists of an agent interacting with an environment.
RL vs. Control Theory
As exemplified in the last paragraph, RL agents are trained to make sequences of actions that maximize some notion of cumulative reward. In reinforcement learning literature, one often refers to the decision-making function as the agent's policy. The goal is to optimize the policy in such a way that maximizes the agent's reward when interacting with the environment. In other words, the problems solved by RL may also be phrased as control problems. The policy that is continuously updated for each simulation cycle may be viewed as the control law used for making optimized actions in the environment. The main difference between traditional control theory and reinforcement learning is that RL involves adaptive learning from interactions, while control theory usually involves pre-designed controllers based on system models. It is due to reinforcement learning's trial-and-error approach to finding optimal policies that reinforcement learning excels in complex, uncertain, dynamic environments where learning from experience is crucial.
Where is RL used today?
Reinforcement learning is for instance used in e-commerce to enhance suggestion systems. By analyzing user behavior and feedback, RL algorithms can learn to suggest products that are more likely to interest the user, thereby improving user experience and increasing sales. For example, an RL-based recommendation system might suggest new products based on past purchases and browsing history, continually refining its suggestions as it learns more about user preferences.
In the gaming industry, reinforcement learning has led to significant advancements, particularly in developing sophisticated game AI. AlphaGO, developed by DeepMind, is a prime example where RL enabled the AI to master the complex game of Go, even defeating world champions. Similarly, RL techniques have been applied to Atari games, allowing AI agents to learn and master these games through trial and error, often achieving superhuman performance.

AlphaGo by Deepmind utilized reinforcement learning methods to beat the top go player Lee Sedol.
RL approaches are also trending in robotics and the development of autonomous vehicles. In robotics, RL is used to teach robots how to perform complex tasks such as object manipulation, navigation, and human-robot interaction. For autonomous vehicles, RL helps in decision-making processes, enabling the vehicle to navigate through dynamic environments, avoid obstacles, and optimize routes based on real-time data.
Generative AI models, such as those used for creating art, music, or text, benefit from RL by incorporating human feedback to refine their outputs. RL allows these models to adjust their generation strategies based on the rewards or penalties received from human interactions. This approach leads to more nuanced and higher-quality outputs that align better with human preferences and creativity.
Future usage of RL
I suspect that RL will become increasingly influential in various industrial sectors over the coming years, particularly in areas such as energy, industrial processes, and manufacturing.
In the energy sector, RL can optimize the management of smart grids and renewable energy sources. By learning from real-time data, RL algorithms can enhance energy efficiency, reduce costs, and ensure reliable energy distribution. For instance, RL can dynamically adjust the supply-demand balance in smart grids, optimize the operation of wind and solar power plants, and improve energy storage systems. RL's ability to adapt to real-time changes and optimize decisions in complex environments makes it particularly useful in the energy sector, where conditions and demand can fluctuate rapidly.
RL has the potential to transform industrial processes, including carbon capture and utilization. RL algorithms can optimize the parameters of carbon capture systems to maximize efficiency and minimize costs. By learning from operational data, RL can enhance the performance of carbon capture technologies, making them more effective in reducing greenhouse gas emissions. RL's adaptive learning capabilities allow it to handle the complexities and variabilities inherent in distributed industrial processes, leading to more efficient and sustainable operations.
In manufacturing, RL can be applied across various stages of the production line, from assembly to maintenance. RL algorithms can help robots learn new tasks, optimize workflows, and ensure precision in repetitive tasks. Predictive maintenance powered by RL can foresee equipment malfunctions, schedule timely interventions, and prevent costly breakdowns. This not only enhances efficiency but also extends the lifespan of machinery. The trial-and-error approach of RL enables continuous improvement and adaptation to changing conditions, making it invaluable in dynamic manufacturing environments.
Conclusion
Reinforcement Learning is a powerful machine learning framework that learns and improves over time by interacting with the environment. It has huge potential to solve complex problems and adapt to dynamic situations. Stay tuned for future blog posts where we will delve deeper into the fascinating world of RL!